
Really, you don’t. Retrieval Augmented Generation (RAG) simply means giving the model relevant documents to use for answering a question. In principle this is a very intuitive and human thing to do. However, given the rate advancements in GenAI are happening, be warned: you do not need RAG.
Lessons from the past:
Memory in Computing
In 1981, a statement attributed to Bill Gates proclaimed that ‘640K ought to be enough for anybody,’ referencing the memory capacity limit for early personal computers. While it’s debated whether Gates ever actually said this1, the quote has become a tech industry legend, symbolizing the often underestimated potential of technological progress. This anecdote serves as a reminder of how past predictions can falter in the face of rapid innovation.
Today, as we are living through an AI revolution, similar bold statements are made about the limitations and capabilities of artificial intelligence systems. One such discussion revolves around the concept of ‘working memory’ in large language models (LLMs) and whether traditional constraints necessitate solutions like Retrieval-Augmented Generation (RAG). RAG systems, designed to extend an AI’s memory and comprehension, represent a significant leap in how machines understand and process long-form information. But as history shows, what we perceive as a limitation today might not be so tomorrow. Are these complex solutions necessary, or will the technology of tomorrow render them obsolete?
Memory in Computer Systems: Abundance and Accessibility
Historically, memory was a critical bottleneck in computer systems. The early days saw stringent limitations, with systems like the IBM PC initially supporting just 640KB of RAM, which dictated what could be effectively computed. Fast forward to today, and the landscape has drastically changed. Memory, both in terms of capacity and cost-efficiency, has improved so significantly that for many applications, it’s no longer considered a constraint. Most modern computing environments operate under the assumption that memory is virtually infinite, focusing instead on optimizing compute power and processing speed.
Context as “Working Memory” for LLMs (Large Language Models)
In humans, ‘working memory’ refers to the part of our memory that is actively holding and processing information. It’s what you use to remember a phone number just long enough to dial it, or to keep track of the ingredients you need while cooking a recipe. It is essential for having even the most basic conversations, without working memory you would not even remember the question you were just asked long enough to answer it.
When it comes to AI, particularly large language models (LLMs) like those used by ChatGPT or translation services, ‘working memory’ serves a similar but more complex role. These AI systems need to ‘remember’ pieces of information from the text they read to make sense of it and generate appropriate responses. However, unlike humans who can easily shift focus and pull in memories from long ago, AI’s ability to keep and use information is more limited.
This limitation is often referred to as the ‘context window’ or ‘context length’ in LLMs. It’s like the AI has a notebook where it can only keep a few pages of notes at a time. If the information it needs to understand or respond to a question is on page 1, and the AI is currently writing on page 10, it might struggle because it can’t see page 1 anymore. This is a significant challenge when dealing with complex conversations or documents that require understanding context over long stretches of text.
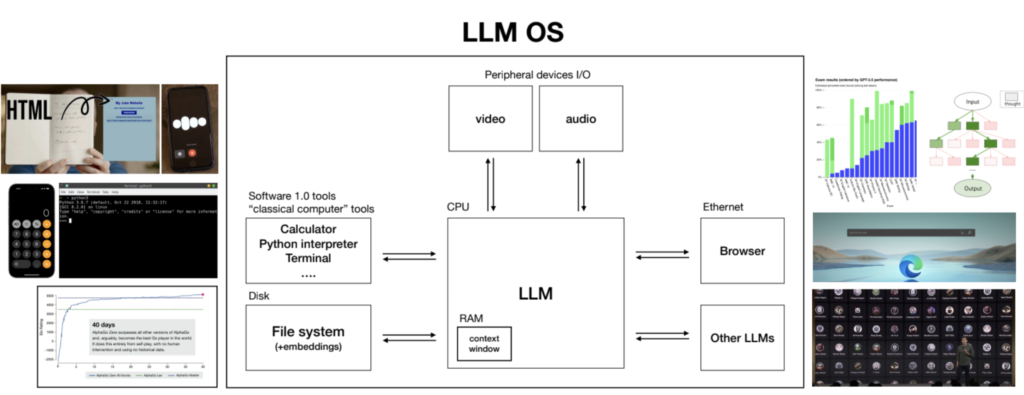
This analogy is certainly not new, one example is Andrej Karpathy’s talk “Intro to Large Language Models”, where he explains the concept of an “LLM OS” and how the context window is the analog to RAM in conventional computers.
What is Retrieval-Augmented Generation (RAG)?
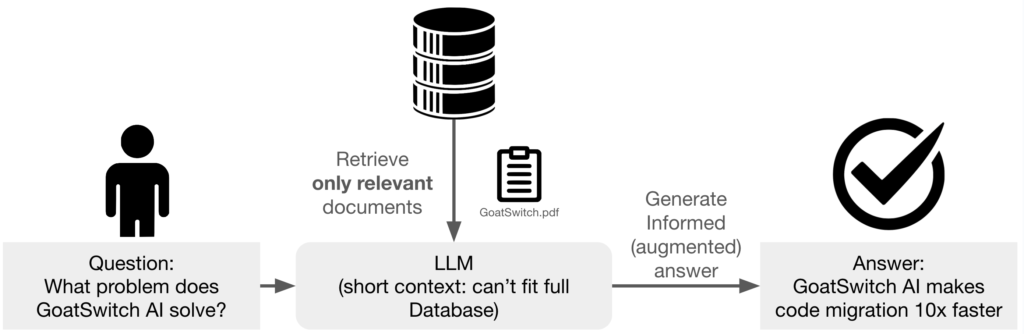
To tackle the limitations posed by the ‘context window’ in large language models, a new approach called Retrieval-Augmented Generation (RAG) has been developed. This innovative technology essentially gives AI a tool to ‘look up’ information outside of its immediate memory—similar to how a student might use library books to supplement their notes.
How RAG Works:
RAG operates by combining the generative powers of a traditional language model with the ability to retrieve external information. When the model receives a prompt or a question, it first looks through a vast database of texts—much like searching through numerous books in a library. It then uses the information it finds to inform and enhance its responses. This means the AI isn’t just relying on the data it was trained on; it’s actively pulling in relevant information as needed.
This process can be split into two main steps:
- Retrieval: The model queries a dataset or a knowledge base to find relevant documents or snippets of text that could contain the needed information.
- Generation: Using both the retrieved data and its pre-existing knowledge, the model generates a response that is informed and accurate, often synthesizing information from multiple sources.
Why RAG Matters:
The ability to access and utilize external information allows RAG-equipped models to handle questions and topics that are beyond their training data’s scope. This is particularly valuable in scenarios where staying current with the latest information is crucial, such as news updates, medical advice, or technological advancements. Moreover, it helps the AI generate more precise and detailed responses, providing a richer and more informative interaction for users.
RAG in Practice:
Imagine an AI tasked with answering questions about recent scientific discoveries. Without RAG, the model might only provide general knowledge based on its last update. With RAG, it can retrieve the latest research papers or data, offering insights that are up-to-date and specific.
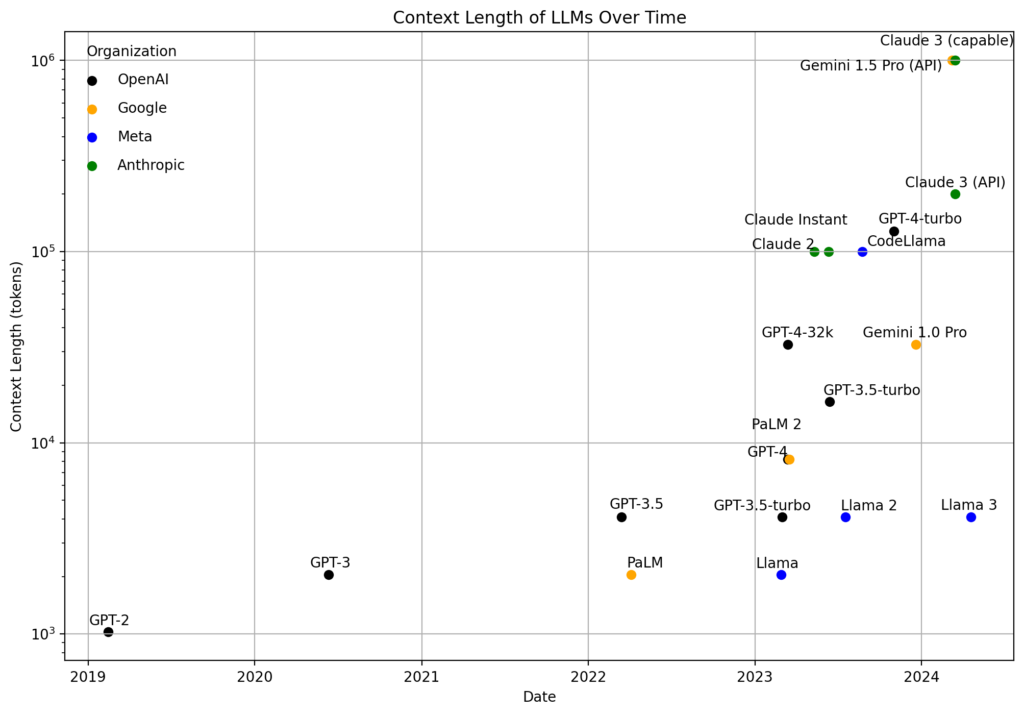
Rapid Growth of Context Sizes in Language Models
The development of language models (LLMs) has been marked by a notable trend: rapidly increasing context sizes. This expansion allows these models to ‘remember’ and process larger blocks of text during interactions, which enhances their ability to understand and generate more coherent and contextually relevant responses.
Early Developments to Modern Capabilities:
- GPT-22: Introduced by OpenAI, GPT-2 featured a context window of 1,024 tokens (~1.5 pages of text).
- GPT-33: Also developed by OpenAI, this model significantly expanded the context window to 4,096 tokens (~6.5 pages of text). This growth allowed for more complex and sustained conversations, enabling chat models like ChatGPT
- GPT-44: The evolution continued with GPT-4, which dramatically increased the context size to 128,000 tokens (~205 pages of text). This extension enables the model to handle much longer narratives and detailed document analysis.
- Anthropic’s Claude 35: Moving forward, Anthropic introduced Claude 3 with a context size of 200,000 tokens (~320 pages of text).
- Google’s Gemini6: Representing a significant leap, Google’s Gemini model boasts a context size of 1,000,000 tokens (~1600 pages of text).
The Future of RAG in an Era of Ultra-Long Context Models and Shrinking Compute Costs
As the capabilities of large language models (LLMs) rapidly expand, with ultra-long context sizes now reaching up to a million tokens and compute costs continually declining, the relevance of Retrieval-Augmented Generation (RAG) comes into question. With these technological leaps, we are entering an era where the traditional advantages of RAG are being overshadowed by more inherently capable systems.
Diminishing Returns of RAG:
- Ultra long contexts: The latest LLMs can manage and integrate vast amounts of data internally. With context windows expanding to unprecedented lengths, these models can maintain extensive dialogues, understand complex narratives, and generate coherent, contextually rich responses without the need for external data retrieval. This intrinsic capability reduces the dependency on RAG, which was primarily designed to compensate for shorter context limitations.
- Cheap compute: The declining cost of computation is making it increasingly economical to operate more powerful models. This shift in the cost dynamics favors running larger, more capable models directly over employing additional layers like RAG. As compute power becomes cheaper and more accessible, the economic justification for using retrieval systems to enhance performance diminishes.
- Simplification: By reducing reliance on RAG, AI systems can become more streamlined and less complex. This simplification can lead to improvements in efficiency, faster response times, and lower overheads in managing and integrating disparate systems. Moreover, simplifying the architecture of AI models could also lead to increased robustness and easier scalability.
The Case Against RAG:
While RAG has been a groundbreaking development, enabling AIs to access external databases and incorporate up-to-date knowledge, the rapid evolution of LLMs suggests that the future may lie in self-contained models that do not require external support to perform at high levels. The ability of these advanced models to process and analyze information within a self-sustained framework challenges the continued necessity of RAG, especially in standard applications where the most recent information is not critical.
PSA: In case you still need RAG
While the case against RAG is a strong one, scaling laws and promises for future capabilities are of little use today. If you find yourself needing a RAG system to navigate through the complexities of the present, don’t worry, we’ve got you covered. Book a free consultation today and let’s figure out how we can make RAG work for you.
Contact us to get started!
- https://quoteinvestigator.com/2011/09/08/640k-enough ↩︎
- https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf ↩︎
- https://arxiv.org/abs/2005.14165 ↩︎
- https://openai.com/blog/new-models-and-developer-products-announced-at-devday ↩︎
- https://www.anthropic.com/news/claude-3-family ↩︎
- https://arxiv.org/abs/2403.05530 ↩︎